
3장 기계 학습과 인식
훈련집합 VS 테스트 집합
훈련집합: 기계 학습 모델을 학습하는데 쓰는 데이터로서 특징 벡터와 레이블 정보를 모두 제공
테스트 집합: 학습을 마친 모델의 성능을 측정하는데 쓰는 데이터로서 예측할 때는 특징 벡터 정보만 제공하고, 예측 결과를 가지고 정확률을 측정할 때 레이블 정보를 사용
규칙기반 방법 VS 기계학습 방법 VS 딥러닝 방법
규칙기반: 분류하는 규칙을 사람이 구현 -> 큰 데이터셋에서는 적용 불가, 데이터가 바뀌면 처음부터 작업해야함
기계학습: 특정 벡터를 추출하고, 레이블을 붙이는 과정은 규칙 기반과 동일, 수작업 특징, 규칙 만드는 일을 기계학습 모델이 자동으로 수행.
딥러닝: 레이블을 붙이는 과정은 기계 학습과 동일 -> 특징 벡터를 학습이 자동으로 알아냄-> 이것을 특징 학습 또는 표현 학습을 한다고 칭함.
딥러닝 장점
- 특징 추출과 분류를 동시에 최적화 하므로 성능이 뛰어나다.
- 인공지능 제품 제작이 빠르다.
원샷 학습: 레이블이 있는 샘플을 하나만 사용해 학습
퓨샷 학습: 몇개의 샘플만을 사용
준지도 학습: 소량의 샘플과 레이블이 없는 대량의 샘플을 같이 사용
기계학습의 전형적인 과정:
데이터 수집-> 특징 추출-> 모델링 -> 예측
분류 그래프 (이는 이미지 첨부가 귀찮아서 그냥 대충 모양 비슷한 그래프의 식으로 올림 ㅎㅎ)
Y=X : 선형 모델로 분류 가능
Y=X^2: 비선형 모델로 분류 가능
Y=X^2이지만 하나만 섞여 있을때: 오류를 허용해야하는 상황
Y=X^2이지만 두개 이상 섞여 있을 때: 오류를 더 허용해야하는 상황
수치형 특징 VS 범주형 특징
수치형 특징: 거리 개념 존재, 실수 또는 이진 값으로 표현
- EX) iris의 네개 특징은 실수
범주형 특징: 학점, 수능등급, 지역 등
- 하지만 범주형 특징은 순서형과 이름형으로 나눠짐
- 순서형:학점, 수능등급 -> 거리개념 존재, 순서대로 부여하면 수치형으로 취급 가능
- 이름형: 혈액형, 지역등으로 거리개념 존재X -> 보통 원핫 코드로 표현(예 A형(1,0,0,0) B형(0,1,0,0)…코드가 0아니면1로 이진 값만 가진다)
일반화 능력이란?
학습에 사용하지 않았던 새로운 데이터에 대한 성능을 측정하는 것
이진분류에서의 긍정과 부정-> 검출하고자 하는 것이 긍정
- EX) 의사가 환자를 찾아낸다-> 환자가 긍정 일반인이 부정
긍정을 긍정으로 예측: 참긍정
긍정을 부정으로 잘못 예측: 거짓부정
부정을 긍정으로 잘못 예측: 거짓 긍정
부정을 부정으로 예측: 참부정
주어진 데이터를 적절한 비율로 훈련, 검증, 테스트 집합으로 나눈다.
- 모델 선택 포함: 훈련/검증/테스트 집합으로 나눈다
- 모델 선택 제외: 훈련/테스트 집합으로 나눈다
교차 검증에서 훈련/테스트 집합으로 나눌때 나타나는 한계점에 대해 서술하고 이에 대한 해결방안에 대해 서술하시오.
발생하는 문제: 우연히 높은 정확률이 나타나거나, 우연히 낮은 정확률이 나타날 수 있다. 그럴 때 사용하는 방법이 k겹 교차 검증인데, 훈련집합을 k개의 부분집합으로 나누어 한개를 남겨두고 k-1개로 학습한 다음 남은 것으로 성능을 측정한다. 그다음 k개의 성능을 평균하여 신뢰도를 높인다. 이때 k를 더 크게 하면 많은 수의 성능을 평가 하므로 신뢰도가 높아지지만, 수행시간이 더 많이 걸리므로 적절 한 값을 선택해야한다. 5,10 사용
-----------------------------------------------------------------------------------------------------------------------
3장에서 나올만한 개념적 문제
3장
- 훈련집합과 테스트 집합의 차이에 대해 설명하시오
훈련 집합은 모델이 직접 학습하는 데이터이다. 특징 벡터와 레이블을 모두 제공한다
테스트 집합은 훈련 집합을 통해 학습된 모델의 성능을 평가할 때 사용하는 집합이다. 특징 벡터는 제공하나 예측 결과를 가지고 정확률을 측정할 때 레이블을 사용한다.2.
하이퍼 매개변수란?
하이퍼 매개변수란 모델의 동작을 제어할 때 쓰는 변수이고,
규칙 기반, 기계학습 방법, 딥러닝 방법에 대해 각각 설명하시오
규칙 기반: 데이터를 분류하는 규칙을 사람이 직접 구현한다 → 규모가 큰 데이터 셋에는 적용불가, 데이터 수정 발생시 처음부터 작업해야한다
기계학습 방법: 특징 벡터를 추출하여 레이블을 붙이는 과정은 규칙기반과 동일하나 분류규칙을 기계학습 모델이 자동으로 수행한다
딥러닝: 딥러닝은 특징 벡터를 수집하는 일을 자동으로 알아내어 분류와 최적화를 동시에 진행하여 뛰어난 성능을 보여준다. + 인공지능 제품 제작 빠름
기계학습의 전형적인 과정에 대해 설명하시오
데이터 수집→ 특징 추출→모델링→예측
범주형 특징과 수치형 특징에 대해 설명하시오
수치형 특징 : 거리 개념이 존재한다 실수 + 이진으로 표기 ex) iris 의 네개 특징은 실수
범주형 특징 : 이름형, 순서형으로 분류 가능
순서형은 거리개념이 존재하고(학점, 수능등급), 이름형은 거리개념이 존재 하지 않는다 ex) 지역이름, 원핫코드
교차 검증에서 훈련/ 테스트 집합으로 나눌 때 나타나는 한계점 및 해결방안
훈련/ 테스트 집합으로 나눌 때 우연히 높은 정확도가 나타나거나, 우연히 낮은 정확률이 나타날 수 있다.
이 떄 사용할 수 있는 방법이 k겹 교차 검증인데, 우선 훈련집합을 k개로 나눈후에 하나를 남겨두고 k-1개로 학습한 뒤에 남은 것으로 성능을 측정하는 방법이다. 이때 k를 크게 하면 많은 수의 성능을 평가 하므로 신뢰도가 넢아지지만, 수행시간이 더 많이 걸리므로 적절한 값을 선택해야
결정 경계를 정하는 문제에서 고려해야하는 사항
결정경계를 정하는 문제에서 고려해야하는 사항은 데이터가 선형 분리가 불가능한 상황에서는 비 선형 분류기를 이용해야하고,
과잉적합을 피해야한다. 과잉 적합은 아웃라이어를 맞히려고 과다하게 복잡한 결정 경계를 만드는 현상을 의미하는데 이때 과잉 적합이 발생하면 훈련 집합에 대한 정확률은 높지만, 테스트 집합에 대한 정확률은 낮아지며 일반화 능력이 저하 문제가 발생한다
결정 경계를 정하는 문제에서 고려해야하는 사항에 대해 설명하시오
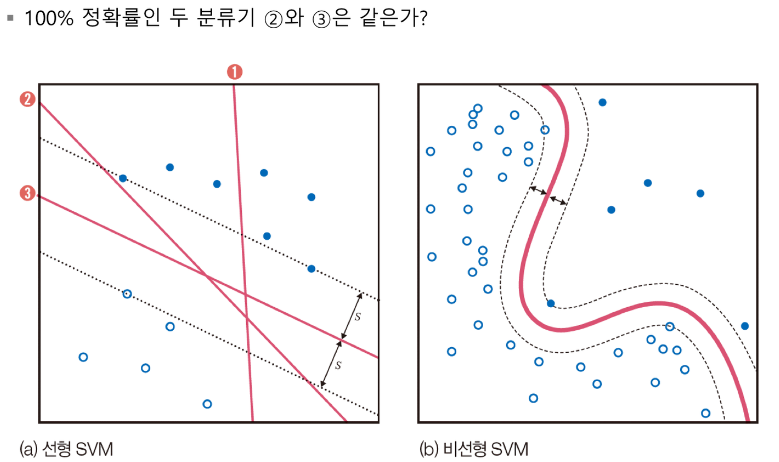
- 데이터가 선형분리 불가-> 비선형 분류기 사용해야함
- 과잉 적합을 피해야한다-> 과잉적합이란 아웃라이어를 맞히려고 과다하게 복잡한 결정 경계를 만드는 현상을 과잉 적합이라고 한다. -> 과잉 적합이 발생하면 훈련 집합에 대한 정확률은 높지만, 테스트 집합에 대한 정확률은 떨어지는 일반화 능력 저하 문제 발생
기계학습의 목적: 일반화 능력을 극대화-> 훈련 집합에 업슨 새로운 샘플이 들어왔을 때 정확하게 분류 하는 것이 목적
위 그림에서 2번의 경계는 푸른 점 부류에 너무 가까워서 조금만 변형이 생겨도 정확도가 낮아질 수 있는 가능성이 큰 반면에 3번은 두 부류에 모두 멀리 떨어져 있으므로 경계를 넘을 가능성이 적다.
'파이썬으로 만드는 인공지능' 카테고리의 다른 글
| [A.I] 파이썬으로 만드는 인공지능 5장 (0) | 2024.06.07 |
|---|---|
| [A.I] 응용 사례 : 나이브 베이즈 영화 추천 (0) | 2024.06.06 |
| [A.I] 파이썬으로 만드는 인공지능 4장 (0) | 2024.06.05 |
| [A.I] 파이썬으로 만드는 인공지능 2장 (0) | 2024.06.03 |
| [A.I] 파이썬으로 만드는 인공지능 1장 (0) | 2024.06.03 |