
8장 시계열 데이터와 순환 신경망
시계열 데이터란 시간 정보가 들어있는 데이터
시계열 데이터는 시간 축을 따라 신호가 변하는 동적 데이터,
앞서 다룬 SVM, 깊은 다층 퍼셉트론, 컨볼루션 신경망 등은 정적 데이터를 입력 → 시계열 데이터 부적합
시계열 데이터를 정적 데이터로 변환하면 정보 손실이 크다
시계열 데이터의 특성:
- 요소의 순서가 중요: 문장의 의미가 회손 될 수 있다
- 샘플의 길이가 다르다: 짧은 발음, 긴 발음
- 문맥 의존성: 앞 과 뒤의 밀접환 관련성
- 계절성: 상추 판매량, 미세먼지 수치 등

딥러닝에서는 시계열 특성을 반영하는 순환신경망 또는 LSTM 사용
순환 신경망의 사용
- 미래 예측
- 언어 번역
- 음성 인식
- 생성 모델
미래 예측을 위한 데이터를 준비하는 과정 (데이터의 길이가 너무 길때)
- 데이터를 준비하는 과정에서 데이터의 길이가 너무 길면, 이를 적절한 크기의 조각들로 분할하여 계산해야하는데, 이때 이러한 조각의 구성요소 의 수를 w 라는 단위로 잘라 여러개의 샘플을 수집한다.
- 그리고 얼마나 미래에 일어날 일인지 수평선 계수 h를 구한다
순환 신경망을 사용하는 이유: 시간에 따라 값이 하나씩 순차적으로 들어오면다는 사실을 반영한 신경망이 필요할때 다층 퍼셉트론을 약간 수정하여 사용
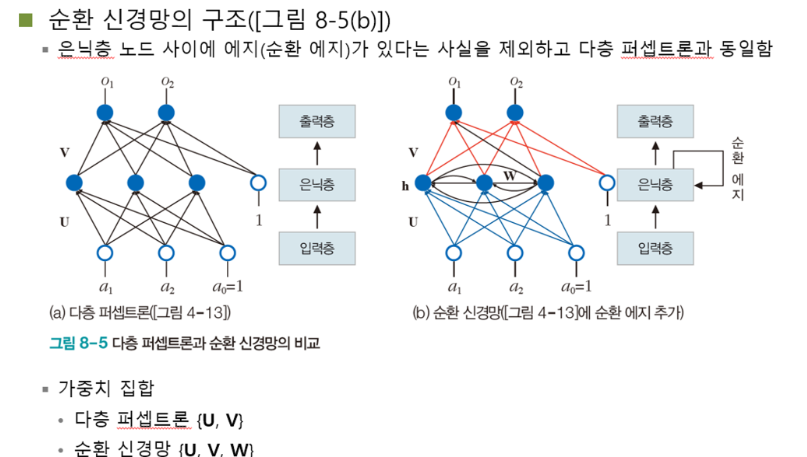
기존에 퍼셉트론과 비교했을 때, 입력 → 은닉층 → 출력층 에서
입력층 → 은닉층 (U)
은닉층 → 출력층(V)
라는 가중치를 곱해주었는데, 순환 신경망은 여기서 은닉층끼리의 순환 가중치를 추가해주면 됨
⇒ 은닉층 → W ← 은닉층
즉 가중치를 (U,V,W)로 설정

즉 요약하자면, h^i 는 서로 2가지의 입력을 받는다. 예를 들어 h^2에서는
- 직전 상태 값 h^1
- 새로운 a의 입력 a^2
즉, 순환 신경망이 동작하는 방식은 위를 풀어 쓴 것 과 같다
→ i 의 순간에 a^i는 가중치 U를 통해 은닉층의 상태 h^i에 영향을 미치고, h^i는 가중치 V를 통해 출력값 o^i에 영향을 미치고 h^i-1은 가중치 W를 통해 h^i에 영향을 미친다.
LSTM(Long Short Term Memory): 게이트라는 개념으로 선별 기억을 확보.
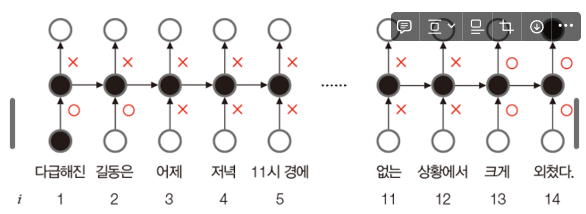
쉽게 설명을 위해 o는 열림, x는 닫힘 (사실 게이트는 0~1의 실수 값으로 열린 정도를 조절)
- 게이트의 여닫는 정도는 가중치로 표현되며, 이는 학습을 통해 알아낸다
- LSTM 가중치는 (U,V,W)에 4개 추가 → (U,Ui,Uo,W,Wi,Wo,V) i는 input, o는 output
LSTM으로 만드는 유연한 구조
적층: 은닉층이 2개인 순환 신경망
양방향: 적층+양방향

양방향 문맥을 다 살필려면 양방향 LSTM 사용
평균 절대값오차(MAE):예측 값과 실제 값 사이의 절대적 차이의 평균
장점: 계산이 간단하고 직관적이다
단점: 예측값의 규모(스케일)에 민감하다

이러한 스케일문제를 해결하는 것이 평균절대값백분율오차
평균절대값백분율오차(MAPE):예측 값과 실제 값 사이의 절대적 차이의 비율의 평균
장점: 예측값의 규모에 비례하여 측정, 비교적 해석 용이
단점: 실제 값이 0에 가까워지면 비율이 크게 왜곡된다



텍스트 데이터의 특성:
- 시계열 데이터로써 시간정보가 있고 샘플마다 길이가 다르다
- 심한 잡음 = 오타
- 형태소 분석 필요
- 신경망에 입력시 기호를 수치로 변환해야하는 번거로움
원핫 코드 변환
EX)
- Freshman loves python.
- We teach python to freshman.
- How popular is Python?
이때 단어를 각각 수집하여 등장 빈도수를 계산하여 딕셔너리에 저정
→ 이때 단어 등장 빈도수에 따라 순위를 부여한다.
예를 들어 Python 이란 단어는 3번 등장, freshman 이라는 단어는 2번 등장하면서 제일 많이 등장하므로 python 이라는 단어의 순위가 1 freshman이라는 단어는 2 순으로 딕셔너리에 저장된다.
그러면 결과 값은이고 이를 원핫코드로 변환해야함 → 이때 등장 단어수만큼 딕셔너리의 길이 설정
[2 3 1] → [010000000] [00100000]…
[4 5 1 6 2 ] …
[7 8 9 1] …
원핫 코드의 문제점
- 사전 크기가 크면 원핫코드는 희소 벡터로써 메모리 낭비
- 단어 사이의 연관 관계 표현 X
이를 해결하기 위한 방법이 단어 임베딩
단어 임베딩이란 단어를 저차원의 공간의 벡터로 표현하는 방법
→ 밀집 벡터로써 수백 차원을 사용하고 단어의 의미를 표현한다 + 신경망 학습으로 알아냄
'파이썬으로 만드는 인공지능' 카테고리의 다른 글
| [A.I] 파이썬으로 만드는 인공지능 9장 (0) | 2024.06.14 |
|---|---|
| [A.I] 파이썬으로 만드는 인공지능 8장 이론 시험 문제 예측해보기 (0) | 2024.06.13 |
| [A.I] 파이썬으로 만드는 인공지능 7장 (0) | 2024.06.09 |
| [A.I] 파이썬으로 만드는 인공지능 6장 (0) | 2024.06.08 |
| [A.I] 파이썬으로 만드는 인공지능 5장 (0) | 2024.06.07 |