
9장 강화 학습과 게임 지능
다중 손잡이 밴딧 문제
1달러를 넣고 손잡이를 골라잡아 당기면 1달러를 잃거나 획득
이때 손잡이 마다 확률이 존재, 사용자는 확률을 알 수 없다
행동 집합 {손잡이1, 손잡이2, 손잡이3 ,… 손잡이 n}
보상 집합 {1,-1}
위 문제는 상태변화가 존재하지 않고 행동 → 보상 사이클 개념
탐험형 정책: 처음부터 끝까지 무작위로 선택
탐사형 정책: 몇번 시도 후에 승률이 가장 높은 것을 채택하는 극단적인 방법
→ 둘 사이의 균형이 중요
그리디 알고리즘: 과거와 미래를 고려하지 않고 순간의 정보만 가지고 현재 최고의 유리한 선택을 하는 알고리즘 → 탐사형에 가까움
ε-탐욕 알고리즘: 기본적으로 그리디 알고리즘이지만 ε 비율 만큼만 탐험을 적용하여 탐사와 탐험의 균형을 추구한다
입실론 그리디 알고리즘은 기본적으로는 그리디 하지만, 입실론 비율만큼 탐험을 적용하여 탐사와 탐험의 균형을 추구한다.
몬테카를로 방법 : 현실 세계의 현상 또는 수학적 현상을 난수를 생성하여 시뮬레이션
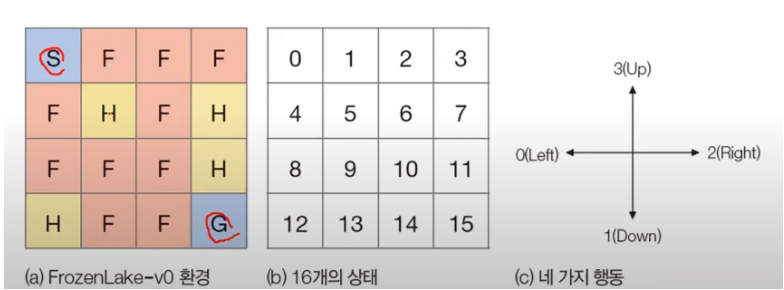
Frozen Lake 문제 : 환경 ,상태, 행동
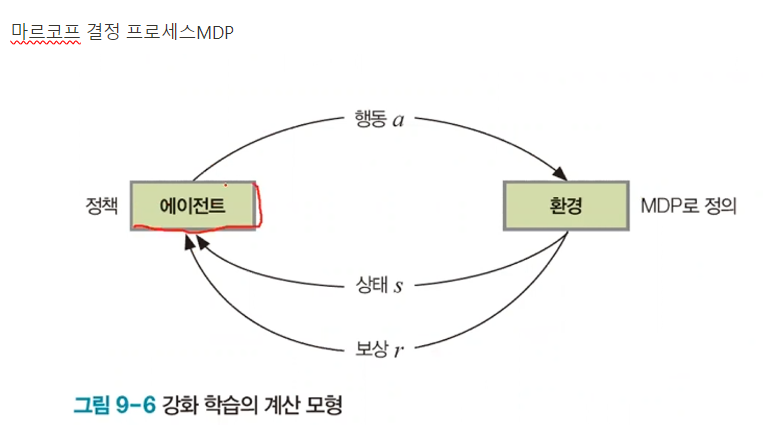
에이전트가 정책에 따라 행동을 주면 환경은 상태를 업데이트 하고 보상을 준다 (사이클)
마르코스 결정 프로세스는 상태, 행동, 보상으로 구성되며 특정 행동을 취했을 때 발생하는 상태변환을 지배하는 규칙 정의
상태 집합: S={s1,s2…}
행동 집합: A={a1,a2…}
보상 집합: R={r1,r2…}
보상이 주어지는 시점이 다르다는 점에서 차이점이 있다
벤딧 - 즉시 보상
Frozen Lake - 지연 보상 ( 대부분의 문제가 지연 보상이다)
상태 전이
- 결정론적 환경(100% 확률로 새로운 상태가 정해진다)
ex 프로즌 레이크 문제에서 right를 선택하면 100프로 오른쪽으로 이동
P(s’ = 2 , r = 0 | s = 1 a = 2) = 1.0 상태 1에서 행동 2를 취하면, 새로운 상태 2로 변경하고, 보상이 0 일 확률이 1.0
- 스토캐스틱 환경 ( 확률분포에 따라 새로운 상태 정해짐)
강화 학습에서 학습 알고리즘이 해야할 일 : 누적 보상을 최대화 하는 최적 정책을 알아내야 한다
최적 정책: 다중 손잡이 밴딧은 승률이 가장 높은 4번 손잡이를 당기는 정책
프로즌 레이크에서는 상태 4에서 행동 1을 취해 안전한 길을 찾는다
최적 정책을 찾는 전략 → 가치 함수(나열법):정책의 품질을 평가하는 함수
신경망 학습과 마찬가지로 ㅠ1으로 초기화 한 후에 ㅠ1을 ㅠ2로 개선하고 ㅠ2를 ㅠ3로 개선해서 최적 정책 ㅠ^ 으로 수렴
프로즌 레이크 문제에서 어떤 상태로 이동할 확률 0.5
마지막 상태에서 도착점으로 들어갈때 확률은 1.0
거기다가 보상까지 1
보상 없으면 0을 곱한다
벨만 기대 방정식
상태들이 서로 밀접한 관련성이 있다
우변에 자기 자신을 포함하는 순환식 형태
예를들어 v1(6) = 시그마 (가능한 모든 행위 조건 - 2 오른쪽, 1 아래) P(a|6)(r+v(s’))
P(2|6)(0+v(7)) + P(1|6)(0+v(10)) =
0.5* 0 + 0.5 * 0.5 = 0.25
할인율을 적용한 벨만 기대 방정식
기존 벨만 기대 방정식에 감마만 추가
에피소드에서 데이터를 수집하는 방법은 상태를 중심으로 에피소드를 자른다
DQN 작동원리
- 초기화: 신경망의 가중치를 랜덤으로 초기화하고, 경험 재현 메모리를 비웁니다.
- 행동 선택: 탐험(Exploration)과 이용(Exploitation) 사이의 균형을 맞추기 위해 ε-탐욕 정책(ε-greedy policy)을 사용하여 행동을 선택합니다.
- 상태 전이 및 보상 관찰: 현재 상태에서 선택한 행동을 수행하고, 다음 상태와 보상을 관찰합니다.
- 경험 저장: 관찰한 경험(상태, 행동, 보상, 다음 상태)을 경험 재현 메모리에 저장합니다.
- 미니배치 학습: 경험 재현 메모리에서 무작위로 미니배치를 샘플링하여 신경망을 학습합니다.
- Q-함수 업데이트: 손실 함수를 통해 Q-함수를 업데이트합니다.
- 타깃 네트워크 업데이트: 일정 주기마다 타깃 네트워크를 업데이트하여 학습의 안정성을 높입니다.
경험 리플레이 메모리의 동작 원리
- 경험 저장: 에이전트가 환경에서 상호작용하면서 얻은 경험(transition)을 메모리에 저장합니다. 경험은 일반적으로 상태(state), 행동(action), 보상(reward), 다음 상태(next state)로 구성됩니다.
- 메모리 유지: 메모리는 한정된 크기를 가지며, 새로운 경험이 추가되면 오래된 경험은 제거됩니다. 이를 통해 최신 경험을 더 많이 반영할 수 있습니다.
- 미니배치 샘플링: 학습 단계에서 메모리에서 무작위로 일정 크기의 미니배치(mini-batch)를 샘플링하여 사용합니다. 이를 통해 학습 데이터의 다양성을 확보하고, 학습 과정의 안정성을 높입니다.
- 추출한 샘플로 바로 학습 X 리플레이 메모리에 저정
- 실제 학습은 리플레이 메모리에서 랜덤하게 추출하여 미니배치로 수행
- 리플레이 메모리가 가득 차면 오래된 것을 삭제하고 추가하는 큐 형태로 구현
'파이썬으로 만드는 인공지능' 카테고리의 다른 글
| [A.I] 응용사례 : 광고 클릭률 시험 문제 예측해보기 (0) | 2024.06.17 |
|---|---|
| [A.I] 파이썬으로 만드는 인공지능 9장 이론 시험 문제 예측해보기 (0) | 2024.06.14 |
| [A.I] 파이썬으로 만드는 인공지능 8장 이론 시험 문제 예측해보기 (0) | 2024.06.13 |
| [A.I] 파이썬으로 만드는 인공지능 8장 (0) | 2024.06.13 |
| [A.I] 파이썬으로 만드는 인공지능 7장 (0) | 2024.06.09 |