

클러스티드 인덱스
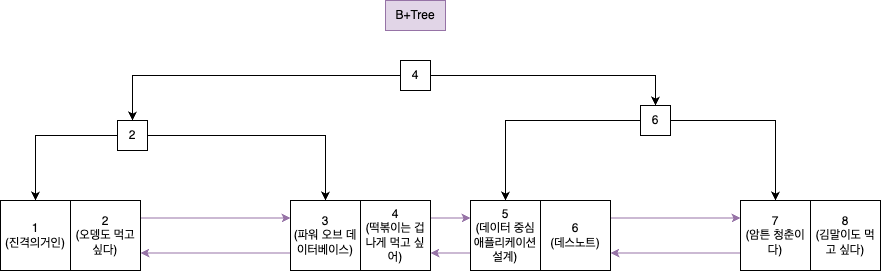
예를 들어 위와 같이 B+트리에 데이터가 저장 되어있다고 가정하자.
id를 기반으로 왼쪽 서브트리에는 더 낮은 id들이, 오른 쪽에는 높은 id들의 데이터가 배치되어 있다.
해당 데이터들은 노드들을 따라가보면 원하는 데이터 (책)의 모든 데이터를 얻을 수 있다.
클러스티드 인덱스란 리프 노드에 위치한 것이 데이터 그 자체인 것을 의미한다.
그래서 인덱스를 따라서 데이터를 찾아내면, 데이터 자체를 조회할 수 있기 때문에 추가적 탐색이 필요 없다.
논클러스티드 인덱스
각 책을 카테고리 단위로 구분하기 위해 인덱스를 생성했다면, 다음과 같은 category B+트리가 생성 될 것이다.
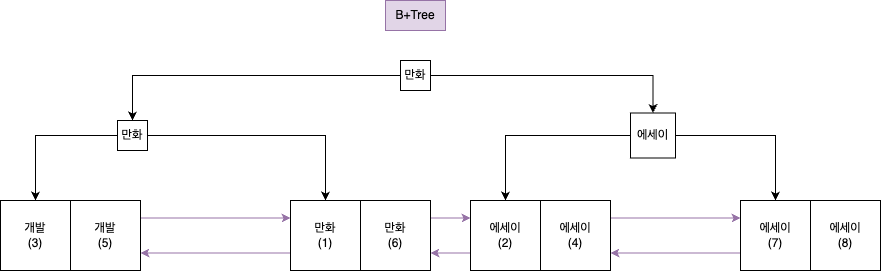
클러스티드 인덱스와 반대로 리프 노드에 위치한 것이 데이터 그 자체가 아니라 데이터의 주소이면 해당 인덱스를 통해 원본 데이터의 id 값을 통해 한번 더 탐색을 진행해야한다.
클러스티드 인덱스 VS 논클러스터드 인덱스
클러스티드 인덱스를 활용하면 한번의 검색으로 데이터를 얻을 수 있고, 논클러스티드 인덱스는 한번 더 탐색해야하기 때문에 클러스티드 인덱스에 비해 비효율적인 방법이다.
이러한 비효율적 작업을 오버헤드가 크다고 표현하는데, 논클러스티드 인덱스가 검색을 위한 간접시간이 더 많으니 오버헤드가 더 크다고 할 수 있다.
커버링 인덱스
클러스티드 인덱스를 확장해서 생각해보면, 우리가 필요한 데이터의 컬럼 값이 인덱스에 모두 포함 되어 있다면 최적화 할 수 있지 않을까?
이렇게 구현한다면 추가적 데이터 조회 없이 곧바로 결과를 가져올 수 있다. 이 개념을 커버링 인덱스라고 한다.
예를 들어 책을 찾는다고 할 때 해당 인덱스에 제목/저자/출판사 를 같이 등록해두게 되면 한번의 인덱스 탐색만으로 필요한 필수 데이터를 한번에 조회할 수 있게 된다.
Random I/O 와 Sequential I/O
데이터베이스는 물리적 디스크에 저장하기 때문에 실제 DB에 자주 접근하게 되면 데이터 조회 성능이 줄어든다.
Random I/O는 찾고자하는 데이터가 여러곳에 분산되어 있어 여러 위치를 랜덤하게 접근해야하는 경우, 디스크 헤더가 여러곳을 찔러봐야하기 때문에 속도가 느려진다.
반면 Sequential I/O는 연속된 데이터를 읽다보니, 디스크 헤더가 이동할 필요 없이 한번에 빠르게 읽을 수 있다.
생각해보면 인덱스를 사용하게 되면, 대상 컬럼을 기준으로 정렬이 되기 때문에, B+트리에서 빠르게 대상 데이터들을 한번에 조회할 수 있다.
즉, 커버링 인덱스를 통하여 디스크 접근 횟수 (랜덤)을 줄이고 디스크 추가 조회 없이 인덱스에서 바로 값을 가져올 수 있다.
커버링 인덱스는 순차 I/O를 통해 쿼리 시간을 단축하고, 대용량 데이터 처리에 더더욱 효과적인 인덱스이다.
'우리 같이 백엔드 하자 > Index' 카테고리의 다른 글
| Index 4편 - MySQL의 구조(Optimizer, Storage Engine), 쿼리 플랜 (1) | 2025.12.17 |
|---|---|
| Index 2편 - Index 구현 (B+Tree) (1) | 2025.12.15 |
| Index 1편 - 단일인덱스와 복합인덱스 (0) | 2025.12.15 |