
이전 포스팅을 요약해서 복습해보자면, 프로세스란 실행 환경과 자원을 제공하는 컨테이너 역할을 하고, 실제 CPU를 사용하여 코드를 한줄씩 처리하는 것은 스레드이다.
CPU 코어가 1개이고 , 프로세스가 2개이며, A프로세스에는 스레드가 1개, B 프로세스에는 스레드가 2개라고 가정하자. 그렇다면 처리 과정은 대략 아래 그림과 같다
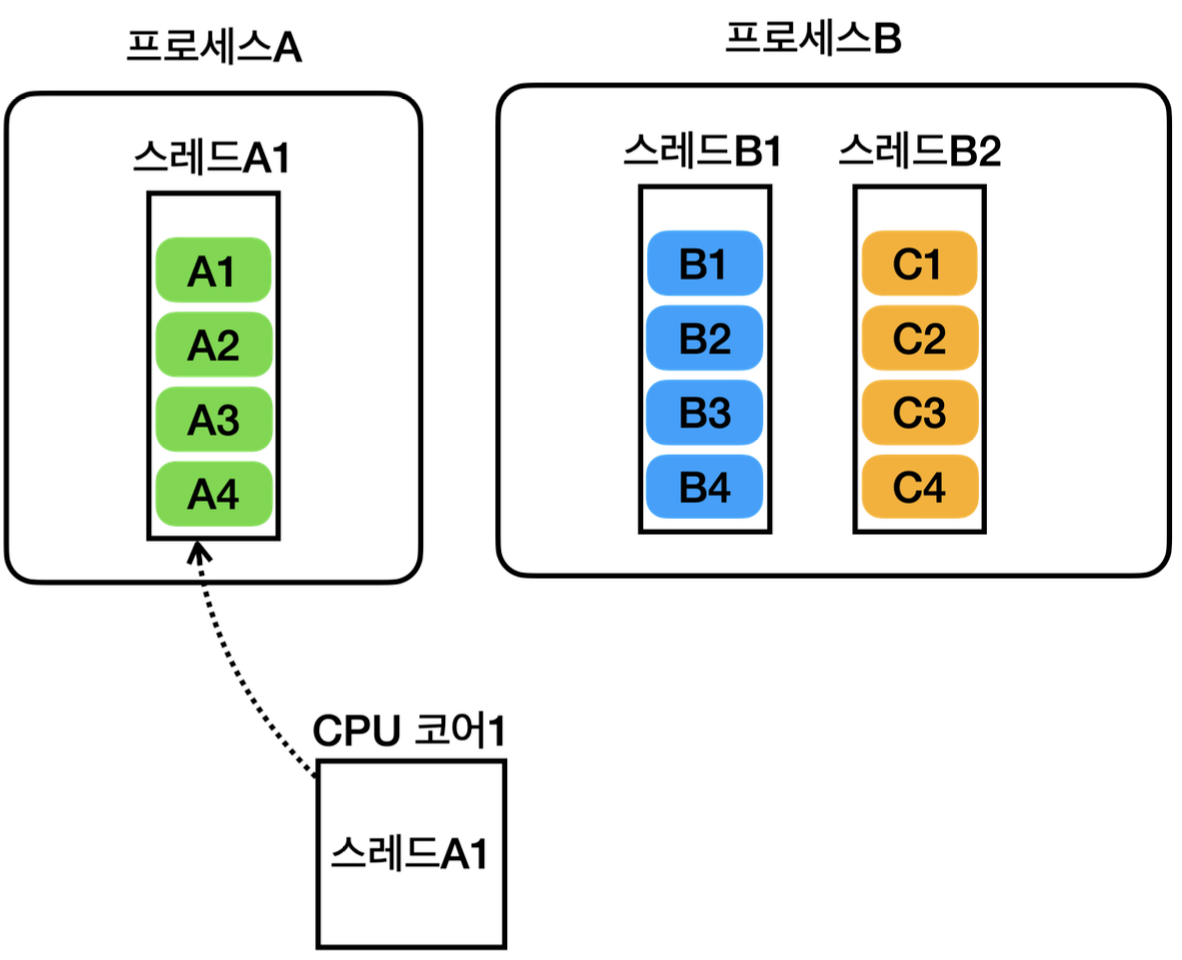

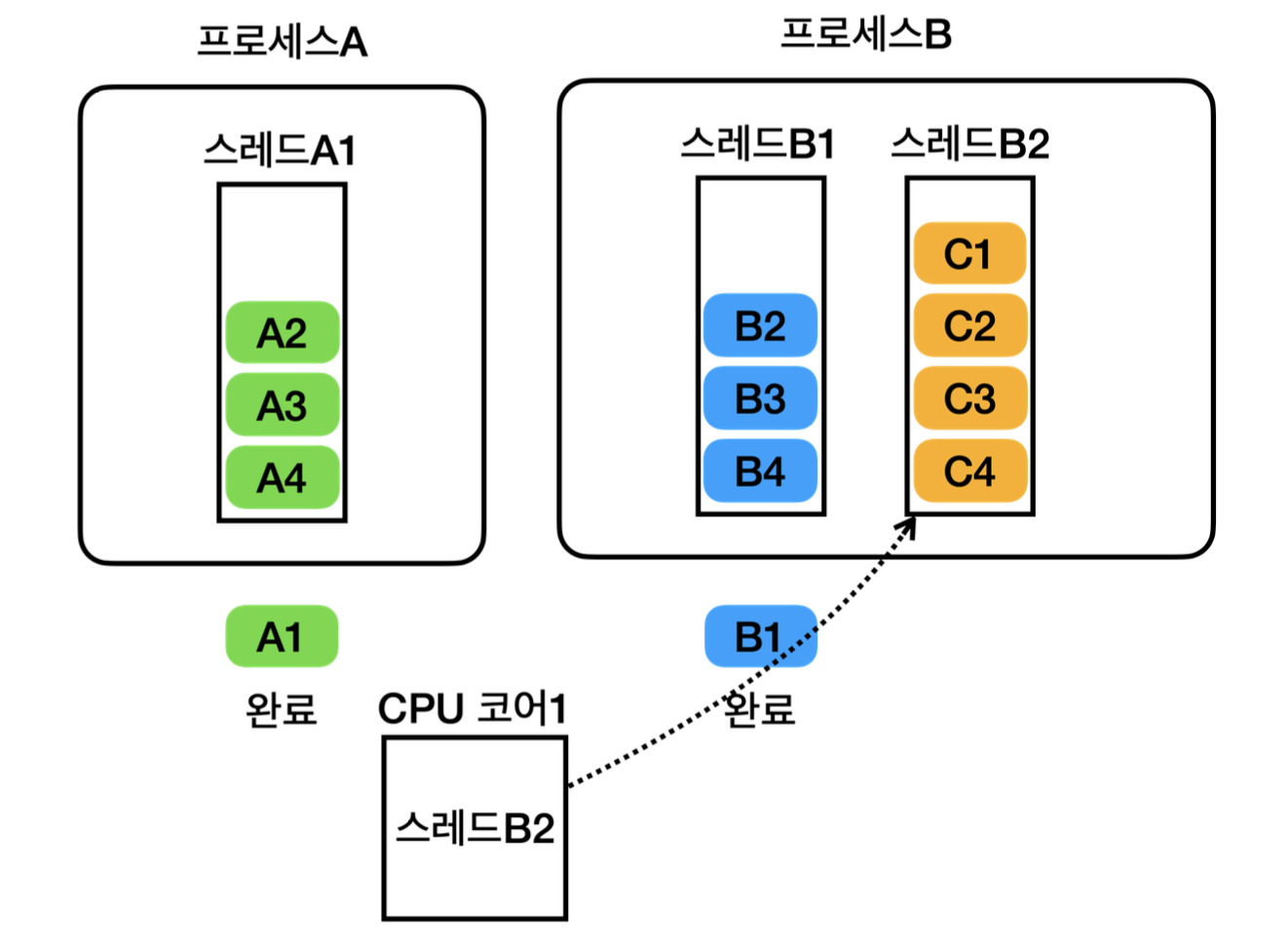
이후 이 과정을 반복하여 모든 프로세스의 스레드를 실행한다.
단일 코어 스케줄링
스케줄링 방법은 따로 포스팅해야할 정도로 길기 때문에, 간단히 언급만 하고 넘어가겠다!
먼저 운영체제는 내부에 스케줄링을 위한 큐를 가지고 있고, 각각의 스레드는 스케줄링 큐에서 대기한다.
그리고 스레드가 처리되는 과정은 아래와 같다.
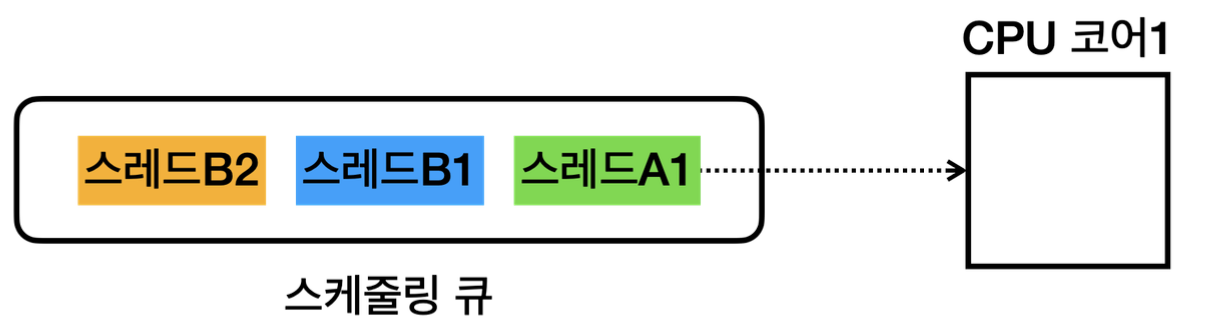
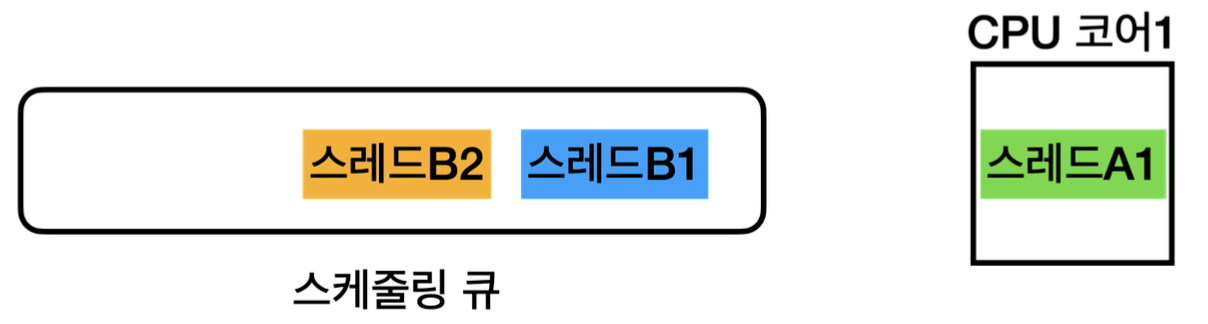
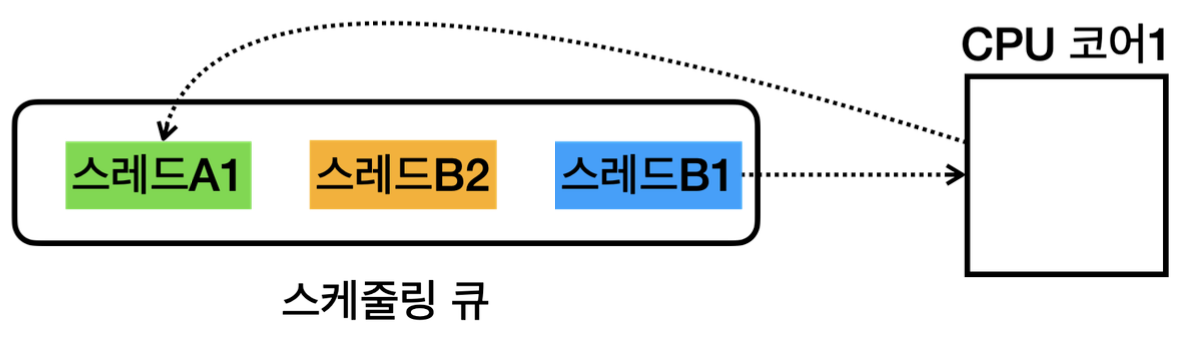
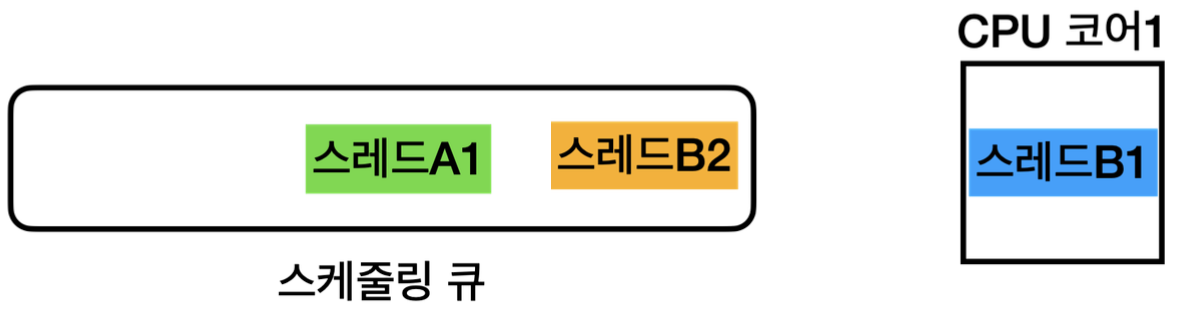
우선 순위가 높은 스레드부터 한 줄씩 코드가 처리되면, 스케줄링 큐의 가장 뒷부분으로 들어가고, 그 다음 우선순위가 높은 스레드가 CPU를 점유하여 코드 수행 및 연산을 수행 하는 과정을 반복한다.
이렇게, CPU 코어 하나로 여러 스레드를 동시에 처리하는 것 처럼 보이게 하는 방식을 단일 코어 스케줄링이라고 한다.
멀티 코어 스케줄링
멀티 코어 스케줄링은 단일 코어 스케줄링에서 CPU 코어개수를 물리적으로 늘린 것이다.
간단히 예시를 보면,
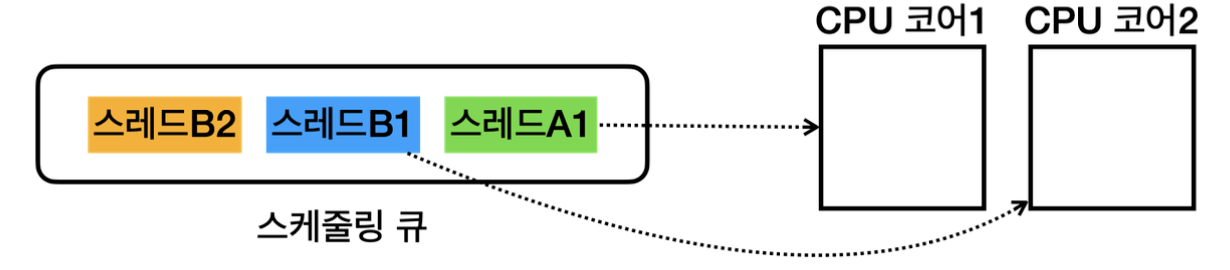

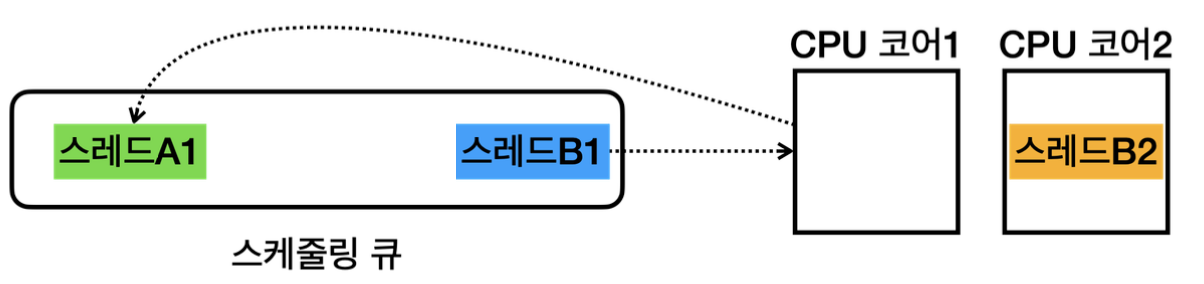

즉, 코어 개수를 늘린 덕분에 실제 물리적으로 여러 스레드를 동시에 실행할 수 있게 되었다.
CPU에 어떤 프로그램이 얼마만큼 실행 될지는 운영체제가 결정하고, 이를 스케줄링이라고 한다.
단순히 작업 소요 시간등을 고려하여 분할하기 보다는 여러 최적화 방안을 통하여 우선순위 얼마만큼 점유할지를 결정하게 된다.
컨텍스트 스위칭
멀티 태스킹이 진행되는 동안, 스레드 A1를 처리하다가 잠시 멈추고 B1을 처리했다고 가정하자.
B1을 처리하다가 다시 A1으로 돌아갈 때, 그냥 A1으로 돌아갈 순 없다. 왜냐하면 이전에 실행하던 A1이 어디까지 수행되고 있었으며, 변수에는 어떤 값들이 들어 있었는지 CPU로 불러 들여야하기 때문이다.
따라서 스레드 A1를 멈추는 시점에 CPU에서 사용하던 값들을 메모리에 따로 저장해두고, 이후에 A1을 다시 실행할 때 메모리에서 값들을 다시 불러와서 처리해야한다. 이러한 과정을 컨텍스트 스위칭 (context switching) 이라고 한다.
그래서 멀티 스레드는 대부분 효율적이지만, 이러한 컨텍스트 스위칭을 진행 하는 과정에서 메모리를 아주 조금 점유하기 때문에, 약간의 비용이 발생한다는 단점이 있다.(그래도 대부분 효율적임)
'Operating System' 카테고리의 다른 글
| [OS] 프로세스(Process)와 스레드(Thread) (0) | 2024.11.03 |
|---|---|
| [OS] 멀티 태스킹 (Multi Tasking), 멀티 프로세싱(Multi Processing) (0) | 2024.11.02 |