
고객 대응 팀에 일하고 있어서 하루 죙일 고객정보를 SELECT 해야하는 상황이라고 가정하자.
고객 센터 문의를 답변하기 위해 고객 정보를 조회 하기 위하여 SELECT * FROM 고객 이름 WHERE ~ 어쩌구와 같은 SQL문을 하루종일 타이핑하고 앉아 있는 거지 효율을 줄이기 위해 등장한 기능이 바로 저장 프로시저 기능이다.
Stored Procedure 란
재사용성이 높은 코드를 하나로 묶어 덩어리로 관리하는 기능을 Stored Procedure 라고 한다.
먼저 프로시저를 만드는 법을 보자. 코드를 보면 이해가 쉽다
DELIMITER $$
$$
CREATE PROCEDURE DB명.프로시저명
BEGIN
SQL문 1;
SQL문 2;
END $$
DELIMITER ;
// 저는 이렇게 해봄
DELIMITER $$
$$
CREATE PROCEDURE 테스트.get_all()
BEGIN
SELECT * FROM product WHERE 가격 > 5000;
END $$
DELIMITER ;BEGIN 과 END 사이에 코드 덩어리들을 넣어주면 된다.
이후엔 CALL 프로시저() 하면 프로시저 안에 모든 코드 덩어리들이 실행되게 된다.

성능과 효율성
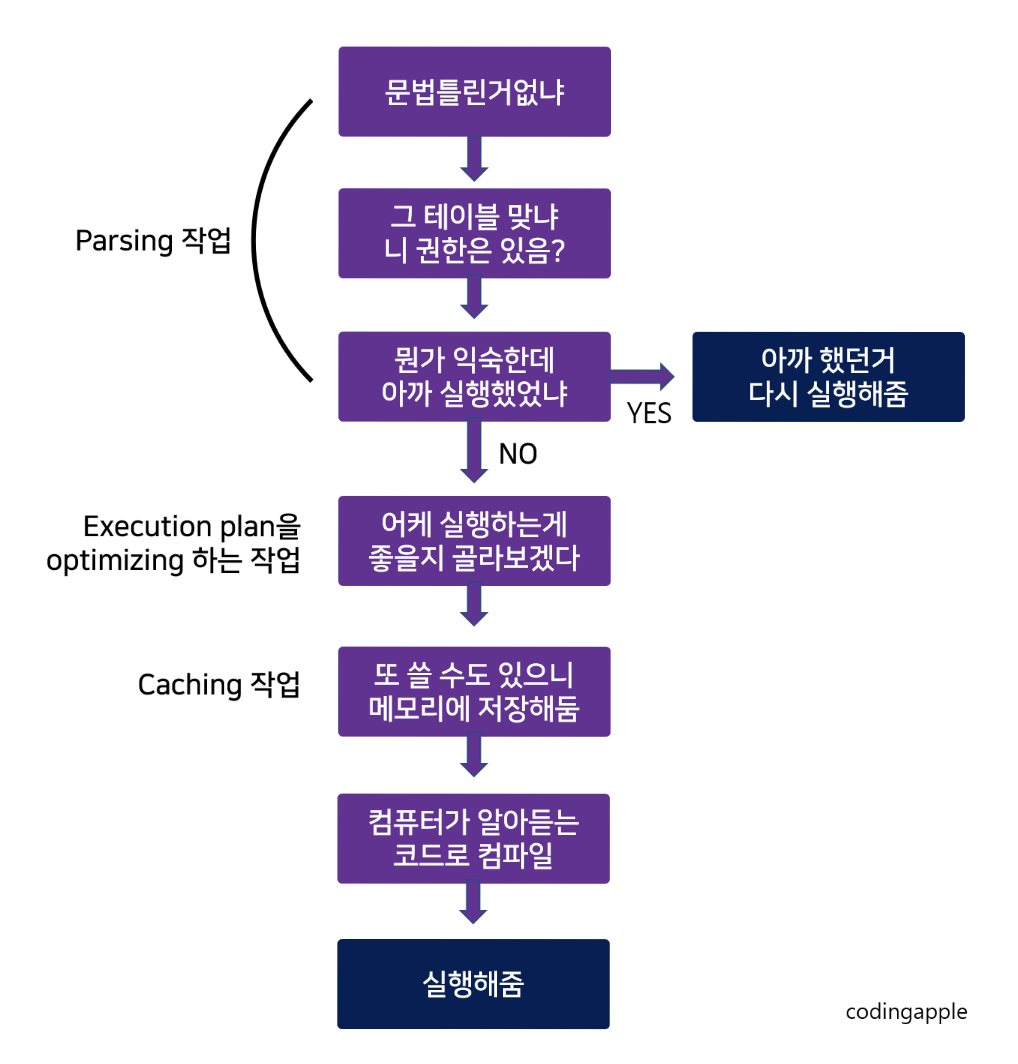
SQL이 실행되는 구조는 세로 구조와 같은데, 저장 프로시저를 쓰면 3번에서 오른쪽으로 빠지는 경우가 많다.
4, 5, 6 단계를 실행하지 않고 3번에서 바로 실행 한다는 점에서 조금 빠를 수 있지만 사실 직접 SELECT 문을 작성하는 것과 크게 차이 없다.
근데 왜 쓰냐
당연히 프로시저는 작업의 효율성을 위해 존재한다.
만약 맨처음에 언급했던 상황(고객 센터 문의를 답변하기 위해 고객 정보를 조회 하기 위하여 SELECT * FROM 고객 이름 WHERE ~ 어쩌구와 같은 SQL문을 하루종일 타이핑하고 앉아 있는 거지 효율) 에서 계속 SELECT 문을 쓰기보단 CALL find_member() 한줄을 통해 복잡한 로직을 모두 처리할 수 있게 된다.
또한 나 말고도 다른 개발자나 마케터가 프로시저의 이름만 보고 어떤 기능을 하는지 판단하여 편하게 SQL문을 가져다 쓸 수 있다는 장점이 있다.
근데 내가 들었던 한가지 문제점이 있는데, 프로시저는 같은 코드만 반복하면서, 특정 회원을 어떻게 조회 하냐? 라는 질문을 할 수 있는데 이를 위해 SQL에서도 기본 프로그래밍 문법 처럼 변수를 사용할 수 있게끔 해준다(사실 파라미터 덕분인데 파라미터를 알려면 변수부터 알아보자).
바로 밑에서 알아보자.
빠르게 SQL 내에 변수 사용하는 방법 알아보기
프로시저는 잠시 잊고, SQL에서 변수 사용하는 문법을 알아보자
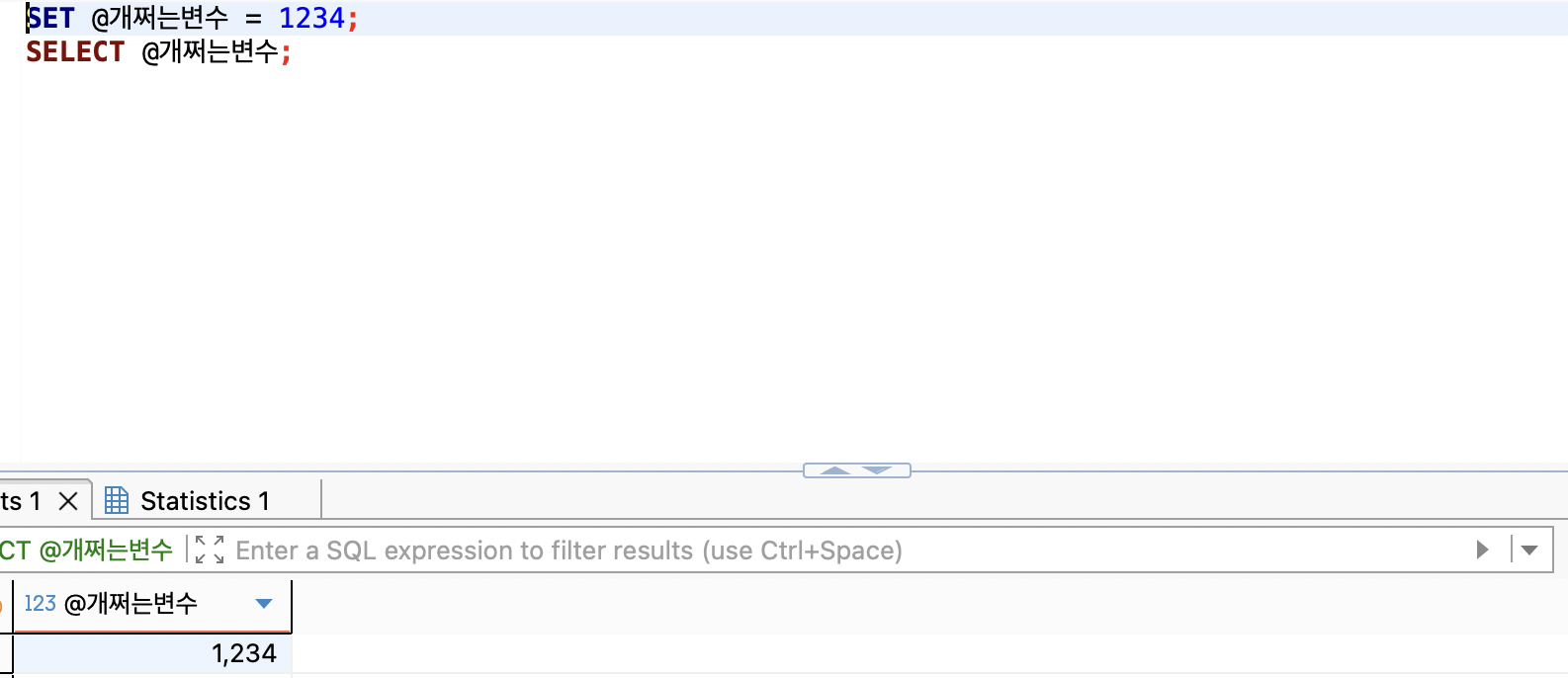
SET @변수명 으로 변수를 설정하면, SELECT @변수명을 통해 가져다 쓸 수 있다.
이를 응용해보면 다음과 같이 쓸 수 있다.
변수에 값을 저장하고 그 변수를 통해 필터링을 할 수 있다.

이제 변수를 알아 봤으니, 프로시저 내부에 변수를 사용하여 프로시저의 재사용성을 더욱 높여보자.
프로시저 내부에 변수 사용하기
기존 변수 사용법과 살짝 다르다.
프로시저 내부에서 변수를 선언할 때는 DECLARE 예약어를 사용하야한다.
이후 선언된 변수에 값을 대입할 때 SET 예약어를 써야한다.
CREATE PROCEDURE mart.var_test()
BEGIN
DECLARE 변수1 INT;
SET 변수1 = 10;
SET 변수1 = 변수1 + 1;
SELECT 변수1;
END이런식으로 변수1이라는 변수를 DECLARE 로 생성하고, SET을 통해 변수에 값을 대입할 수 있다.
그럼 아마 값이 11이 나올 듯?
DECLARE 변수 vs @변수
가장 큰 차이점은 변수 사용의 스코프이다.
@변수는 user variable 로써, 한번 만들면 DBMS 세션이 종료될 때까지 유지 된다. 그리고 한번 설정해 놓으면 SQL 파일 모든 곳에서 호출할 수 있다.
반면 DECLARE 로 설정한 변수는 프로시저 내부에만 사용이 가능하다. 즉 프로시저 내부를 스코프로 가지고 있어 @변수를 쓰는것보다 안정성이 우수하다.
두번째 차이점은 변수 소멸시점이다.
@변수는 DB연결 종료시 사라지는데, DECLARE 변수느 프로시저가 실행을 마치면 바로 소멸되게 되어 있다.
즉, 프로시저는 호출 될때마다 리셋된다고 생각하면 편하다.
그래서 프로시저 내부에는 @변수 문법을 아예 못쓰나?
그건 아니다. 프로시저 내부에도 쓸 수 있다.
DROP PROCEDURE IF EXISTS mart.var_test;
DELIMITER $$
CREATE PROCEDURE mart.var_test()
BEGIN
SET @나이 = @나이 + 10;
SELECT 나이;
END
$$
DELIMITER ;
SET @나이 = 10;
CALL mart.var_test();
CALL mart.var_test();
CALL mart.var_test();이런 프로시저가 있다고 했을 때, @나이 변수는 DB연결이 끝날때까지 전역으로 유효하기 때문에 값이 리셋되지 않고 유지하게 된다. 마치 stateful 하다고 느껴진다.
재사용성 또 증가 - parameter 적용
아까 말한 프로시저로 계속 바꿔 사용자를 검색해야할 때는 모든 유저에 대해 프로시저를 만들어야 하냐? 라는 질문에 고개를 들어 파라미터를 보게 하라 라고 말하고 싶다.
기본 프로그래밍 언어에서 메서드를 뽑을 때 파라미터 넘기는 것과 똑같다.
문제 해결을 위한 파라미터를 적용한 예시 프로시저 코드는 다음과 같다.
DELIMITER $$
$$
CREATE PROCEDURE members.find_member(name varchar(30))
BEGIN
SELECT * FROM members WHERE member_name = name;
고객 정보 변경을 위한 UPDATE / DELETE 문들 추가 가능;
.
.
END
$$
DELIMITER ;
// 호출하는 SQL
CALL members.find_member('호날두')이런식으로 작성하면 프로시저 안에 있는 쿼리들에 name을 대입하여 사용할 수 있게 된다.
위 예시 같은 경우 호날두의 정보를 조회 하고, 수정할 수 있게 된다.
참고로 여러 파라미터를 선언할 수 있고 선언시 반드시 파라미터명 자료타입 을 준수하여 선언해야한다.
SQL 내부에서 능률 올리고 싶으면 프로시저를 쓰자 ~
'DataBase > SQL' 카테고리의 다른 글
| [SQL] TABLE 대신 VIEW를 쓰는 이유는 뭘까? (0) | 2025.07.25 |
|---|---|
| [SQL] 테이블을 안전하게 관리하는 기초 - Constraints 제약 걸기 (0) | 2025.07.21 |
| [SQL] GUI에 의존하지 말고 DDL 직접 씁시다 (0) | 2025.07.21 |
| [SQL] IF / CASE 조건문 (0) | 2025.07.21 |
| [SQL] 실습용 리그오브레전드 챔피언 테이블 공유 [수정] (0) | 2025.07.21 |