
group by절은 데이터에서 의미를 찾고 싶을 때 쓰는 문법이다.
select * 를 통해 전체 데이터를 기준으로 계속 검색하면 성능이 똥구려지게 된다.
즉, 우리는 컬럼 내의 중복되는 데이터들을 그룹지어 필터링하게 되면, 성능도 좋아지고 의미 있는 통계를 낼 수 있게 된다.
group by 써보기
먼저 출신지로 그룹화를 해보자.
SELECT region, count(region) FROM LOL_CHAMPIONS_SAMPLE GROUP BY region;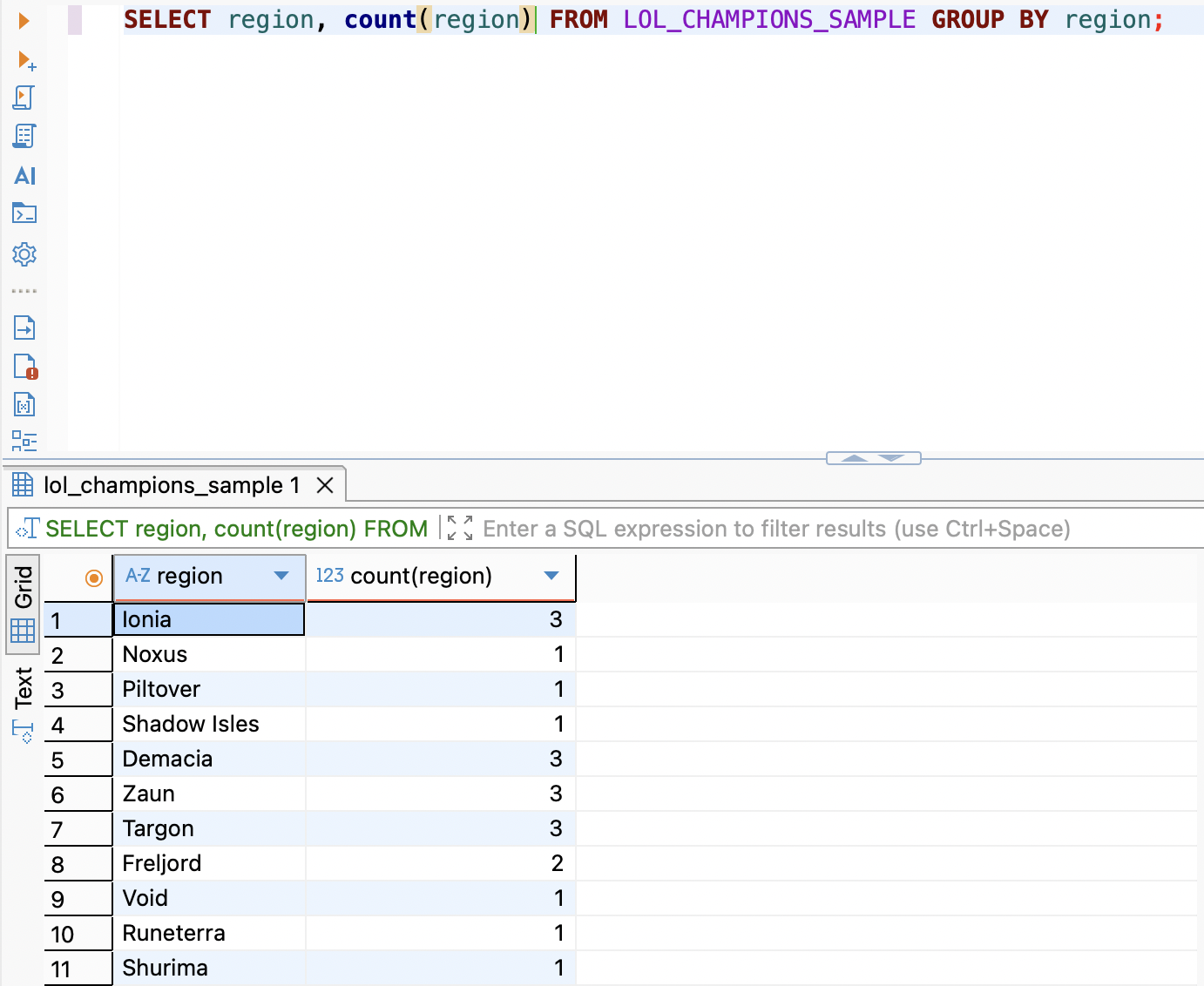
출신지별로 몇명의 챔피언이 존재하는지 그룹으로 출력할 수 있게 되었다. (일종의 DISTINCT 같다)
이렇게 group by 는 특정 컬럼에 중복되는 값들이 존재한다면 그 값들을 그룹지어 집계함수를 통해 의미 있는 통계를 획득할 수 있다 !
그리고 당연히 group by 문법은 중복되는 값들이 있는 카테고리 컬럼에 주로 사용한다
그룹화 + 필터링
이전에 필터링은 WHERE 쓰면 된다고 했다. 하지만 Group By를 통해 그룹화 된 목록에서는 Having 이라는 문법을 써야한다
그룹화를 한 결과에서 필터링을 해보고 싶으면 group by + having을 쓰면 된다.
SELECT region, count(region)
FROM LOL_CHAMPIONS_SAMPLE
GROUP BY region HAVING region = 'demacia';
필터링 할 때 WHERE vs HAVING
WHERE 과 HAVING은 용도가 비슷하지만, 아래처럼 차이점이 존재한다.
Having 은 group by된 결과를 필터링할 때 사용할수 있다. 그래서 반드시 group by 뒤에만 올 수 있다.
Where 은 테이블 전체 데이터 출력에 대해 필터링이 필요할 때 사용하면 된다.
그래서 한 쿼리에 하나만 쓸 수 있나요
아니다. 둘다 쓸 수 있는 예시를 보자
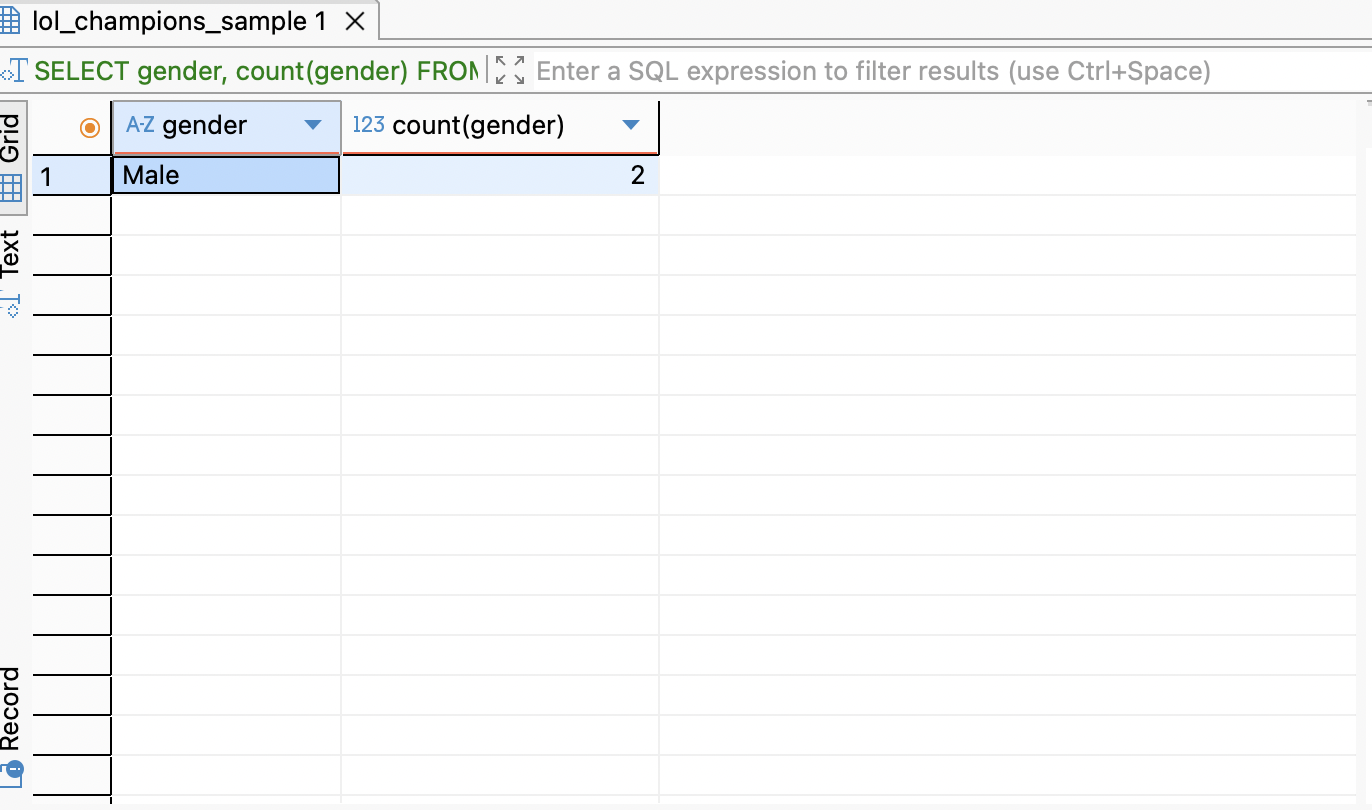
SELECT gender, count(gender)
FROM LOL_CHAMPIONS_SAMPLE
WHERE REGION = 'demacia'
GROUP BY gender HAVING GENDER ='male';이렇게 쓰면 먼저 출신이 데마시아인 챔피언들을 거른 결과에서, 성별을 기준으로 그룹을 짓고(male, female) 남성인 챔피언만 출력할 수 있게 된다.
SELECT / FROM / WHERE / GROUP BY / HAVING / ORDER BY 외우지 말자
이거 데이터베이스 전공책에서 외우라고 나와 있는데, 사실 외우기보단 각자 어떤 역할을 하는지 생각해두면 딱히 외우지 않아도 사용할 수 있다 ~
'DataBase > SQL' 카테고리의 다른 글
| [SQL] IF / CASE 조건문 (0) | 2025.07.21 |
|---|---|
| [SQL] 실습용 리그오브레전드 챔피언 테이블 공유 [수정] (0) | 2025.07.21 |
| [SQL] 서브쿼리 쓰는 법 (0) | 2025.07.16 |
| [SQL] 결과 컬럼 사칙 연산 + 문자 함수 (0) | 2025.07.16 |
| [SQL] 통계 - ALIAS와 집계함수 (0) | 2025.07.16 |