
이번에도 코테를 풀며 늘 데이터가 추가되는 상황에서 늘 ArrayList를 사용했다.
자바가 제공하는 라이브러리가 분명 최적화가 잘 되어 있기 때문에 그냥 ArrayList를 쓰면 된다고는 하지만, 데이터를 앞쪽 인덱스에 삽입하는 경우가 많을 때는 확실히 LinkedList가 유리하다.
평소에 LinkedList를 잘 사용을 하지 않아서, 구조를 다시금 이해 할겸 스스로 구현해보았다.
참고로 LinkedList는 배열리스트처럼 인덱스만 딱 찍어 탐색할 수 없기 때문에 이전 노드의 next 필드의 값을 통해 접근 하는 방식을 사용해야한다. -> 이 사실만 알면 구현은 어렵지 않다.
구현
public class MyLinkedList<E> {
private Node<E> first;
private int size = 0;
// 최초 노드가 비어있으면 새로 추가 , 아니라면 맨뒤에 이어 붙이기
public void add(E e) {
Node<E> newNode = new Node<>(e);
if (first == null) {
first = newNode;
} else {
Node<E> lastNode = getLastNode();
lastNode.next = newNode;
}
size++;
}
// 마지막 노드를 찾는 방법은 결국 처음부터 끝까지 뒤지는 법
private Node<E> getLastNode() {
Node<E> lastNode = first;
while (lastNode.next != null) {
lastNode = lastNode.next;
}
return lastNode;
}
// 특정 부분에 노드를 추가하려면? -> 가장 앞에 , 가장 앞이 아니라면 -> 두가지 조건을 구현
private void add(int index, E e) {
Node<E> newNode = new Node<>(e);
// 첫번째에 추가한다면? -> index = 0
// 추가하는 노드의 next에 현재 첫번째 노드의 주소를 넣어주면 된다
if (index == 0) {
newNode.next = first;
first = newNode;
} else {
Node<E> prev = getNode(index - 1);
newNode.next = prev.next; // 기존이 가르키고 있던 다음 노드를 이제 얘가 가르켜야함
prev.next = newNode;
}
size++;
}
public E set(int index, E element) {
Node<E> x = getNode(index);
E oldValue = x.data;
x.data = element;
return oldValue;
}
public void remove(int index) {
// 지우고 싶은 노드
Node<E> removeNode = getNode(index);
if (index == 0) {
// 첫번째 노드가 가르키고 있던 두번째 노드가 첫번째 노드가 됨
first = removeNode.next;
} else {
Node<E> prev = getNode(index - 1);
prev.next = removeNode.next;
}
makeNodeNull(removeNode);
size--;
}
private void makeNodeNull(Node<E> removeNode) {
removeNode.data = null;
removeNode.next = null;
}
public E get(int index) {
Node<E> node = getNode(index);
return node.data;
}
public Node<E> getNode(int index) {
Node<E> x = first;
for (int i = 0; i < index; i++) {
x = x.next;
}
return x;
}
@Override
public String toString() {
return "MyLinkedList{" +
"first=" + first +
", size=" + size +
'}';
}
public static class Node<E> {
E data;
Node<E> next;
public Node(E data) {
this.data = data;
}
@Override
public String toString() {
StringBuilder sb = new StringBuilder();
Node<E> x = this;
sb.append("[");
while (x != null) {
sb.append(x.data);
if (x.next != null) {
sb.append("->");
}
x = x.next;
}
sb.append("]");
return sb.toString();
}
}
}LinkedList는 배열리스트처럼 인덱스만 딱 찍어 탐색할 수 없기 때문에 이전 노드의 next 필드의 값을 통해 접근 하는 방식을 사용해야한다라는 사실만 알고 이으면 크게 어려운 코드는 없다.
어려울 땐 그림을 그립시다
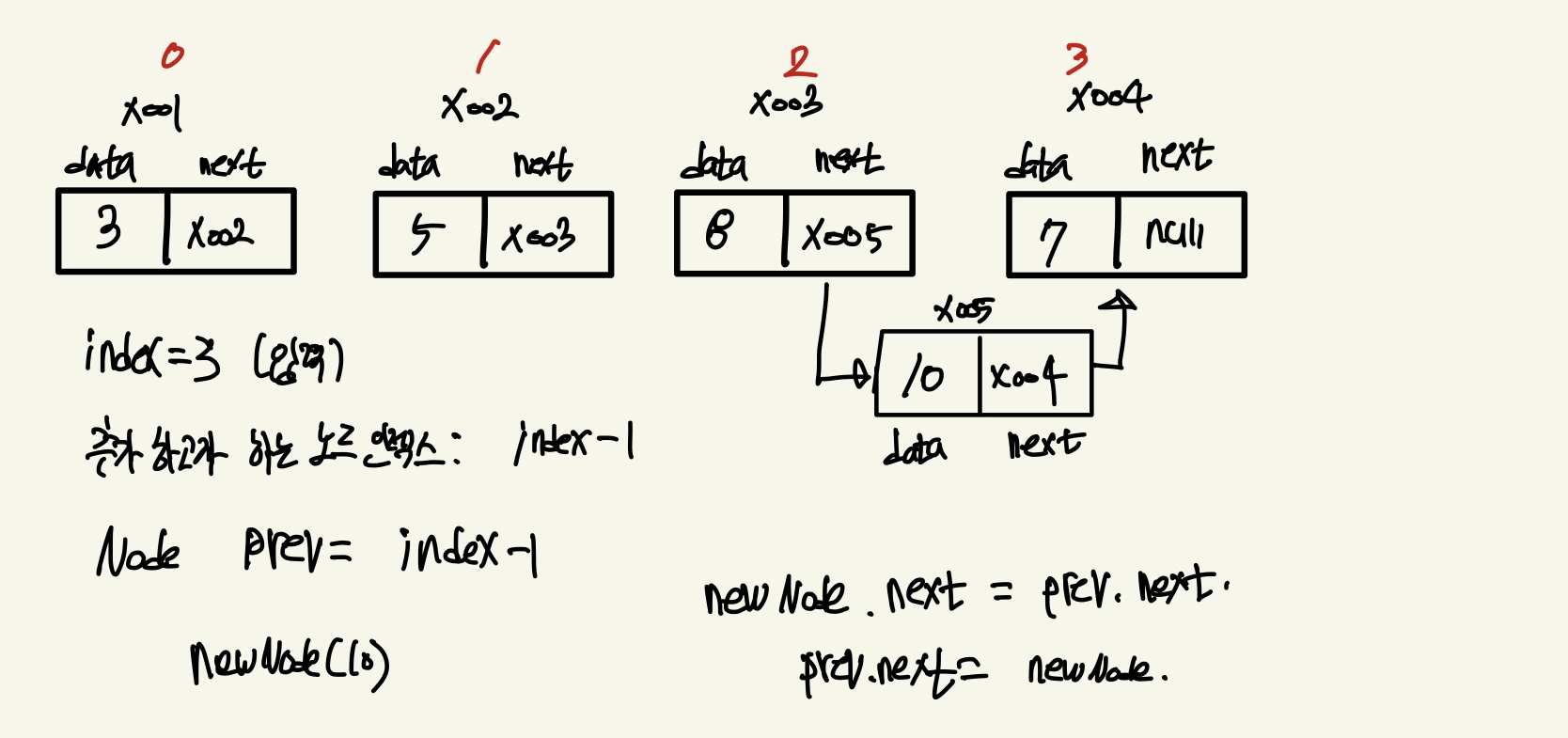
노드 추가
노드가 추가되는 과정 정도만 그림으로 그려봐도 나머지 메서드들은 이해가 쉬울 것이다
(참고로 빨간 색으로 적어둔 인덱스는 실제 존재하는 개념이 아닌 논리적으로 임의로 작성한 인덱스이다)
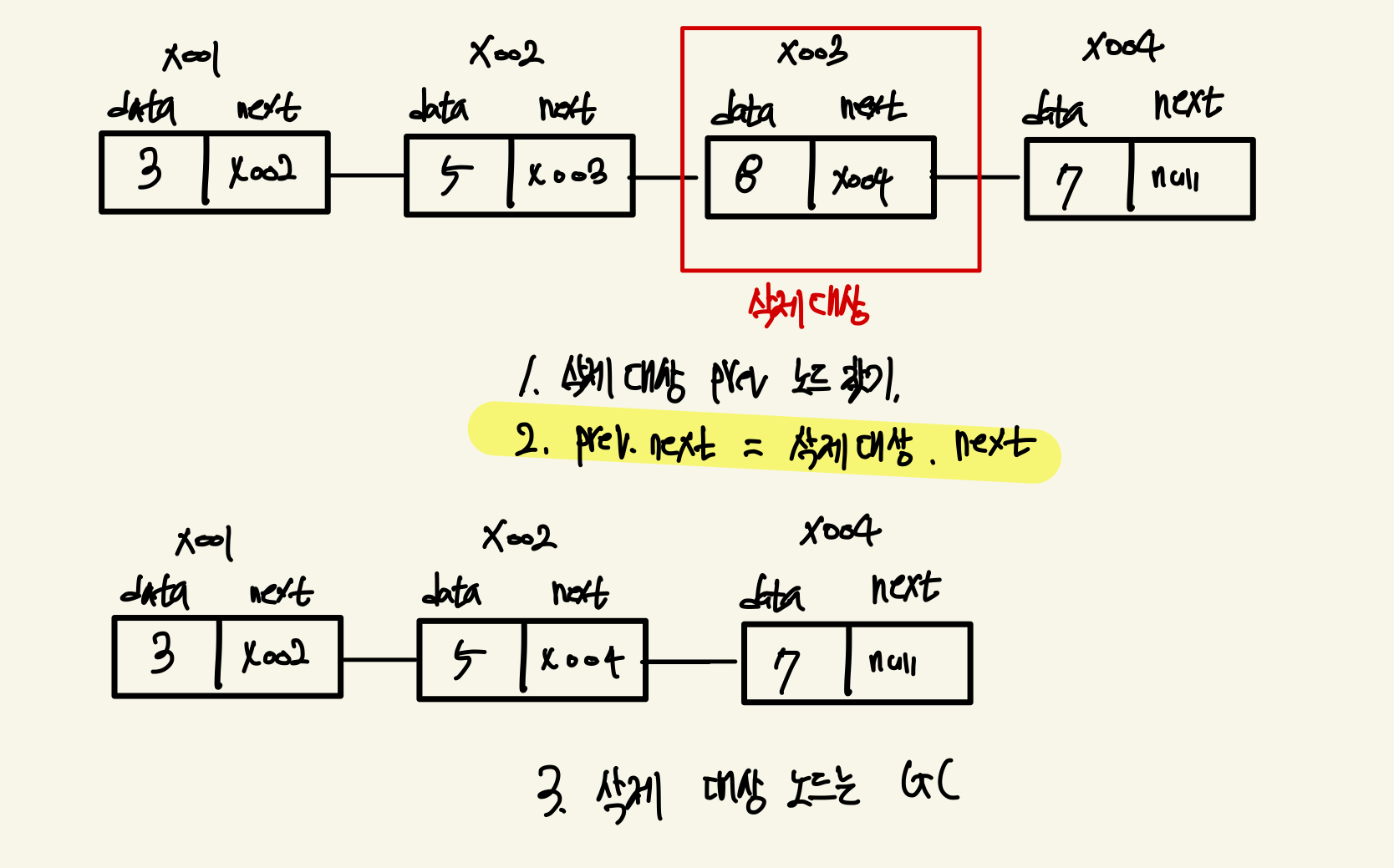
노드 삭제
결과
public class MyLinkedListMain {
public static void main(String[] args) {
MyLinkedList<String> myLinkedList = new MyLinkedList<>();
System.out.println("== 노드 추가 ==");
myLinkedList.add("Ronaldo");
myLinkedList.add("Messi");
myLinkedList.add("Son");
System.out.println(myLinkedList);
System.out.println("== 노드 삭제 ==");
myLinkedList.remove(0);
System.out.println(myLinkedList);
System.out.println("== 다시 호날두 추가==");
myLinkedList.add("Ronaldo");
System.out.println(myLinkedList);
}
}
ArrayList vs LinkedList 시간 복잡도
| 기능 | ArrayList | LinkedList |
| 인덱스 조회 | 배열 리스트는 인덱스를 통한 빠른 접근 -> O(1) | Head 노드부터 순차적으로 접근 -> O(n) |
| 검색 | 노드를 전부 돌며 == 비교 -> O(n) | 노드를 전부 돌며 == 비교 -> O(n) |
| 앞에추가(삭제) | 제일 앞 위치 찾기 -> O(1) , 해당 주소공간 기준 뒤로 모두 밀어야함 -> O(n) = 즉 O(n+1) | 새로 추가할 노드에 기존의 첫번째 노드의 주소값만 추가하면 됨 -> O(1) |
| 뒤에추가(삭제) | 인덱스로 제일 끝을 한번에 찾아서 추가 가능 -> O(1) -> 데이터 이동이 필요 없으므로 O(1) = O(2) | Head 노드부터 마지마까지 타고 타고 타고들어가야 하기 때문에 마지막 노드를 찾는 것 -> O(n) + 노드 추가 -> O(1) = O(n+1) |
| 평균추가(삭제) | 평균은 항상 중간에 있다고 생각하기 때문에 노드를 찾는 시간 복잡도-> O(n) | 평균은 항상 중간에 있다고 생각하기 때문에 노드를 찾는 시간 복잡도-> O(n) |
결론은 데이터를 조회할 일이 많고 뒷부분에 데이터를 추가한다면 배열리스트가 보통 더 낫다. 다만 앞쪽에 데이터를 삽입하거나 삭제할일이 빈번하게 일어난다면 링크드 리스트를 사용하는 것이 더 좋은 성능을 보여준다 !
(하지만 자바 컬렉션은 이중 연결리스트로써 우리가 사용하는 수준에선 비슷비슷하게 성능을 내도록 잘 최적화가 되어있다ㅋㅋ)
'Java > Collections' 카테고리의 다른 글
| [Java] 컬렉션 - Array (배열) / 전,중,후 데이터 삽입 (0) | 2024.11.15 |
|---|---|
| [Java] 컬렉션 - Iterable, Iterator 와 for- each 문 (2) (0) | 2024.10.26 |
| [Java] 컬렉션 - Iterable, Iterator 직접 구현해보기 (1) (0) | 2024.10.26 |
| [Java] 제네릭 (Generic) (2) (0) | 2024.10.10 |
| [Java] 제네릭이 필요한 이유 (Generic) (1) (0) | 2024.10.07 |